
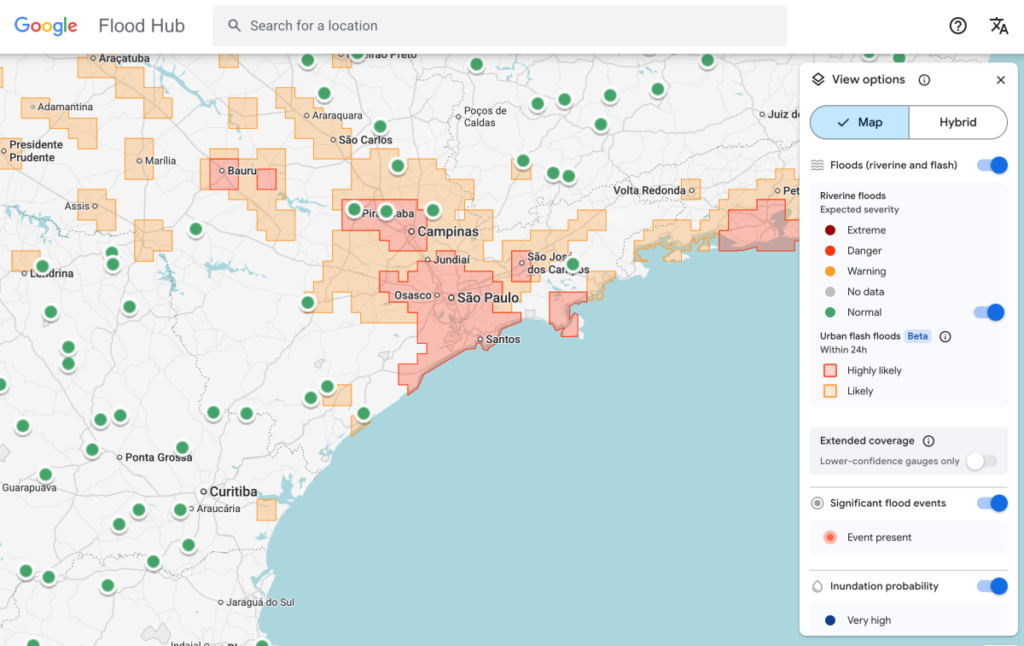
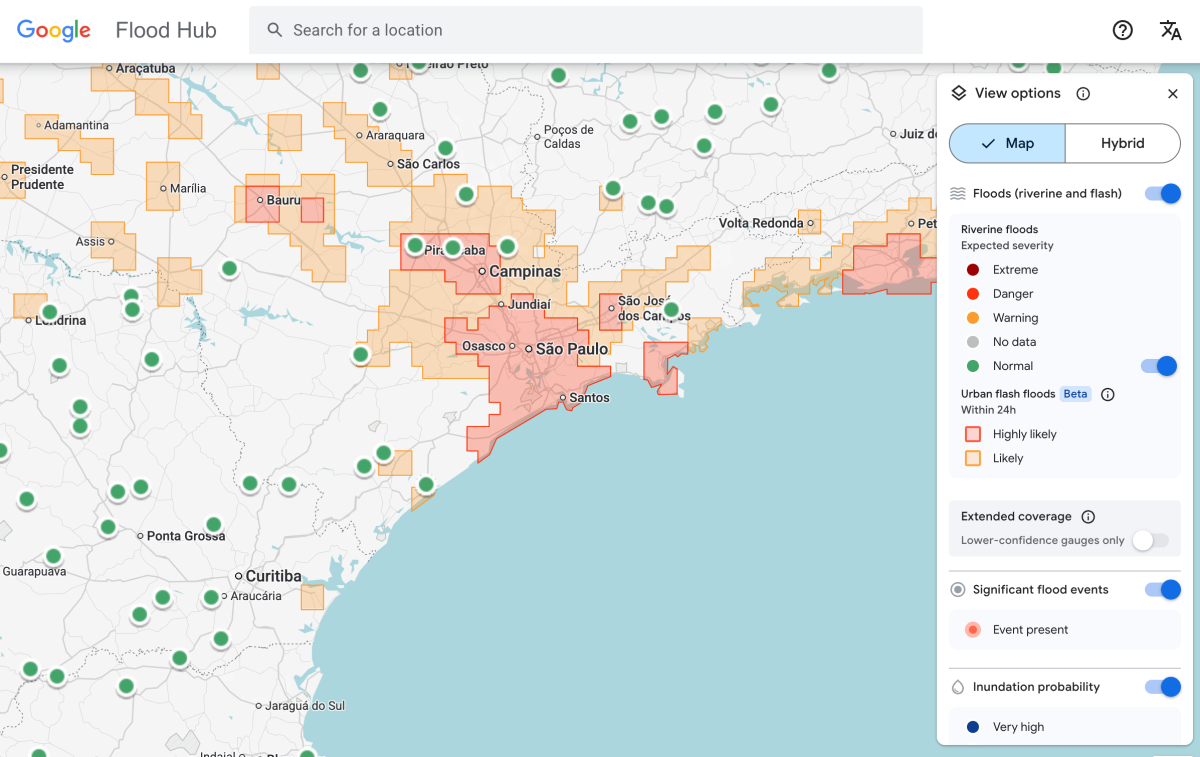
फ्लॅश पूर हा जगातील सर्वात घातक हवामान घटनांपैकी एक आहे, ज्यामध्ये दरवर्षी 5,000 हून अधिक लोकांचा मृत्यू होतो. ते अंदाज लावणे सर्वात कठीण देखील आहेत. पण Google ला वाटतं की बातमी वाचून ती समस्या अगदीच कमी झाली आहे.
मानवाने भरपूर हवामान डेटा एकत्र केला असताना, अचानक पूर फारच अल्पकालीन असतो आणि सर्वसमावेशकपणे मोजले जाऊ शकत नाही, तापमान किंवा नदीच्या प्रवाहाचे कालांतराने निरीक्षण केले जाते. त्या डेटा गॅपचा अर्थ असा आहे की सखोल शिक्षण मॉडेल, जे हवामानाचा अंदाज लावण्यास अधिक सक्षम आहेत, फ्लॅश फ्लडचा अंदाज लावण्यास सक्षम नाहीत.
त्या समस्येचे निराकरण करण्यासाठी, Google संशोधकांनी मिथुन वापरला – Google चे मोठे भाषा मॉडेल – जगभरातील 5 दशलक्ष बातम्यांच्या लेखांची क्रमवारी लावण्यासाठी, 2.6 दशलक्ष वेगवेगळ्या पुराचे अहवाल वेगळे केले आणि त्या अहवालांचे रूपांतर केले. एक जिओ-टॅग केलेली वेळ मालिका “ग्राउंडसोर्स” असे डब केले. गुगल रिसर्च प्रोडक्ट मॅनेजर गिला लोइक यांच्या म्हणण्यानुसार, कंपनीने अशा प्रकारच्या कामासाठी भाषा मॉडेल वापरण्याची ही पहिलीच वेळ आहे. संशोधन आणि डेटा संच होता सार्वजनिकरित्या शेअर केले गुरुवारी सकाळी.
ग्राउंडसोर्स वास्तविक-जगातील आधाररेखा म्हणून, संशोधक एक मॉडेल प्रशिक्षित केले हवामानाचा जागतिक अंदाज ग्रहण करण्यासाठी आणि दिलेल्या भागात अचानक पूर येण्याची शक्यता निर्माण करण्यासाठी लाँग शॉर्ट-टर्म मेमरी (LSTM) न्यूरल नेटवर्कवर तयार केलेले.
Google चे फ्लॅश फ्लड अंदाज मॉडेल आता कंपनीच्या 150 देशांमधील शहरी भागातील जोखीम हायलाइट करत आहे फ्लड हब प्लॅटफॉर्म, आणि जगभरातील आपत्कालीन प्रतिसाद एजन्सीसह त्याचा डेटा सामायिक करत आहे. अँटोनियो जोसे बेलेझा, दक्षिण आफ्रिकन डेव्हलपमेंट कम्युनिटीचे आपत्कालीन प्रतिसाद अधिकारी, ज्याने Google सह अंदाज मॉडेलची चाचणी घेतली, त्यांनी सांगितले की यामुळे त्यांच्या संस्थेला पुराला अधिक जलद प्रतिसाद देण्यात मदत झाली.
मॉडेलला अजूनही मर्यादा आहेत. एक तर, हे अगदी कमी रिझोल्यूशन आहे, 20-चौरस-किलोमीटर क्षेत्रामध्ये धोका ओळखतो. आणि हे यूएस नॅशनल वेदर सर्व्हिसच्या फ्लड ॲलर्ट सिस्टीमइतके अचूक नाही, कारण Google च्या मॉडेलमध्ये स्थानिक रडार डेटा समाविष्ट नाही, ज्यामुळे पर्जन्यवृष्टीचा रिअल-टाइम ट्रॅकिंग शक्य होते.
तथापि, मुद्दा असा आहे की हा प्रकल्प अशा ठिकाणी काम करण्यासाठी डिझाइन केला गेला आहे जेथे स्थानिक सरकार महागड्या हवामान-संवेदनशील पायाभूत सुविधांमध्ये गुंतवणूक करू शकत नाहीत किंवा हवामानविषयक डेटाच्या विस्तृत नोंदी नाहीत.
टेकक्रंच इव्हेंट
सॅन फ्रान्सिस्को, CA
|
13-15 ऑक्टोबर 2026
“आम्ही लाखो अहवाल एकत्रित करत असल्यामुळे, ग्राउंडसोर्स डेटा सेट प्रत्यक्षात नकाशाचे संतुलन राखण्यास मदत करतो,” ज्युलिएट रोथेनबर्ग, Google च्या रेझिलिन्स टीमचे प्रोग्राम व्यवस्थापक, या आठवड्यात पत्रकारांना म्हणाले. “हे आम्हाला इतर प्रदेशांमध्ये एक्स्ट्रापोलेट करण्यास सक्षम करते जेथे जास्त माहिती नाही.”
रोथेनबर्ग म्हणाले की टीमला आशा आहे की लिखित, गुणात्मक स्त्रोतांकडून परिमाणवाचक डेटा संच विकसित करण्यासाठी LLMs वापरणे इतर क्षणभंगुर-परंतु-महत्त्वाच्या-ते-पूर्वानुमान घटनांबद्दल डेटा संच तयार करण्याच्या प्रयत्नांवर लागू केले जाऊ शकते, जसे की उष्णतेच्या लाटा आणि चिखलाच्या स्लाइड्स.
जलविद्युत कंपन्यांसारख्या ग्राहकांसाठी नदीच्या प्रवाहाचा अंदाज घेण्यासाठी तत्सम डीप लर्निंग मॉडेल्स वापरणारी कंपनी अपस्ट्रीम टेकचे सीईओ मार्शल माउटेनॉट म्हणाले की, सखोल शिक्षण-आधारित हवामान अंदाज मॉडेल्ससाठी डेटा एकत्रित करण्याच्या वाढत्या प्रयत्नांचा Google चे योगदान हा एक भाग आहे. Moutenot सह-स्थापना dynamical.orgसंशोधक आणि स्टार्टअपसाठी मशीन लर्निंगसाठी तयार हवामान डेटाचा संग्रह क्युरेट करणारा गट.
“डेटा टंचाई हे भूभौतिकशास्त्रातील सर्वात कठीण आव्हानांपैकी एक आहे,” माउटेनॉट म्हणाले. “त्याचबरोबर, खूप जास्त पृथ्वी डेटा आहे, आणि नंतर जेव्हा तुम्हाला सत्याच्या विरूद्ध मूल्यमापन करायचे असेल तेव्हा पुरेसे नाही. तो डेटा मिळविण्यासाठी हा खरोखर सर्जनशील दृष्टीकोन होता.”
Comments are closed.